
Security of data driven decision-making
/Our decisions processes become more data driven, in individual, social and global scope. This is a good and natural trend, which can give us hope for more accurate and rational decisions. It is possible due to 3 major changes: we have much more data, algorithms and models useful in practice, and computing resources that are easily available. These changes are not disconnected, but rather we should consider them the foundation upon which our decision processes can be constructed. Data driven decision processes therefore take place in socio-technical systems and include at least two levels: the actual decision processes, with social and business dimensions, and the level of data analysis with the software and other technical components. It is critical to have consistency between these two levels as the outcome of decision-making depends on results from underlying data analysis.
In complex systems, many things can go wrong. Different elements of socio-technical systems are susceptible to failures caused by random errors or by intentional actions of 3rd parties. In the second case, we can talk about threats against decision processes, which can be defined as any activities aimed at disrupting their execution or changing their outcome. It is interesting to note that even though the goals of an attacker are usually related to the decision processes (and their results), the actual attacks are more likely to be implemented at the data analysis level. This is simply where we have software components that can be effectively attacked. The decision process can therefore be attacked indirectly, through data analysis solutions, upon which they depend.
Figure 1 includes a simple model of a socio-technical system used in a decision-making with examples of security relevant questions that can be asked regarding its critical components. This system includes two human decision makers, with shared goals and priorities, who use internal data and analysis solutions. In addition to that, there are some external data sources and analysis services separated by the trust boundary. When looking at such a system from a security point of view, we would usually start with the inbound data flows – since all untrusted input data needs to be validated. If we were concerned about the privacy of our data, we should also look at the outbound data flows, to get full understanding what data are exported to systems outside our control.
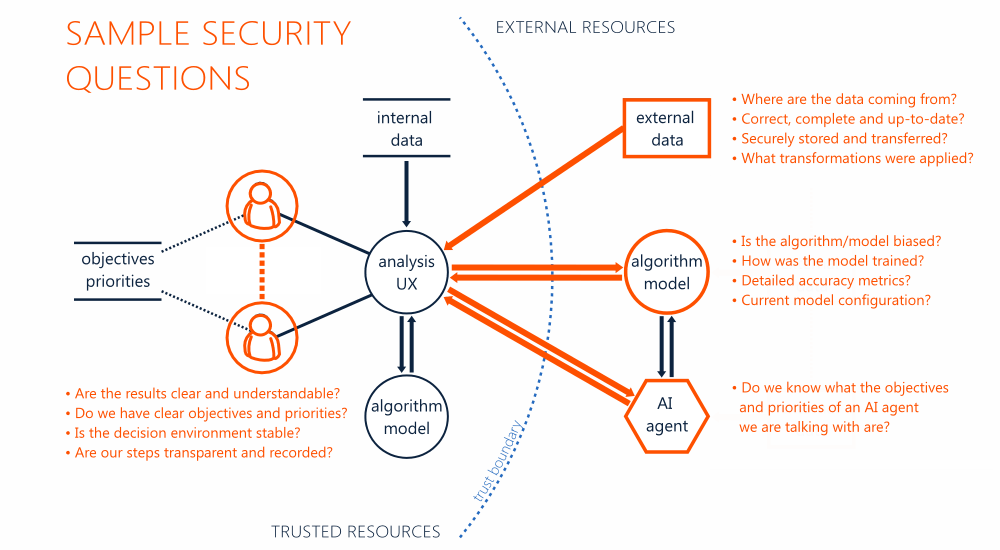
Figure 1. A model of a socio-technical system in a decision-making with examples of security questions regarding its critical components
Such a review quickly becomes much more complex when we move to data analysis scenarios as the base for decision-making.
- In the scope of external data sources, we are not only interested in the format of the data, but also in their quality, credibility or completeness. Can we trust the data to accurately represent the specific phenomena we’re interested in? Please note, that questions like that are not only applicable to data we consume directly, but also to data used by any analysis service we interact with.
- When it comes to external analysis services, there is a lot of discussion about algorithm bias or the practical quality of models. It doesn’t help that many algorithms and models are black boxes due to their proprietary nature or selected business models. And again, this brings us to the questions about trust – will we get the results that we need and expect?
- The 3rd group of key elements includes decision makers, who need to apply the results to the context of specific problem domain and decision situation. Their roles, tasks and types of interactions depend on a specific application scenario, but they are always operating under some constraints (e.g. time pressure), with cognitive limitations, that can be taken advantage of.
- This model will get even more interesting with AI agents joining our decision processes and operating as frontends to external analysis services or as active participants. In interactive cooperation scenarios, it is harder to control what information we are sharing. The questions about operational objectives and priorities of the agents will become very relevant.
We cannot focus only on benefits and opportunities of new technologies and scenarios; we need to think also about new threats and their implications. Security is critical for any practical applications, that obviously includes also decision-making based on data analysis. We need to design these processes to be reliable, trustworthy and resistant to attacks. This applies even to basic scenarios, with seemingly simple decisions like selecting an external data source or trusting a provider of data analysis services with our data. In the following post, we will talk about using experience from information and software security to better understand our systems and making more informed decisions.
This series of posts is based on the presentation made during Bloomberg Data for Good Exchange Conference, on September 24th 2017 (paper, slides).


